Enhancing AMBOSS search evaluation with ChatGPT-generated judgment lists
This article describes our early experiences of using ChatGPT to evaluate how accurate the results of the AMBOSS search engine are. We compare a gold standard judgment list created by medically trained raters to judgment lists generated by GPT-3.5 (ChatGPT) and GPT-4.
How are search engines evaluated – offline vs. online evaluation
Our search engine answers millions of different search queries from hundreds of thousands of unique users every day. Changes to the search engine influence whole classes of queries. A simple visual check of a handful of search results is, thus, not a reliable method of performance evaluation. It needs to be automated and systematic.
To ensure that any changes we make to the search engine are actually improvements, we employ a number of different evaluation methods, which can broadly be split into online and offline measures.
Online measures are behavioural performance indicators calculated from tracking data. As well as the relevance of results, they also cover UX/UI performance of the search interactions.
Offline measures are evaluated against a gold standard set of queries and their results. So far, we’ve been using an open source tool called Quepid to collect gold standard judgment lists from medically trained raters. Offline measures only evaluate raw result relevance.
This post focuses on the creation of gold standard judgment lists for offline evaluation.

The rating process
Judgment lists are created by rating search queries that have been grouped into cases. A typical case samples 150 search queries from a specific segment of our user base. Let’s use the example case of sampling 150 search queries from US physicians during a night shift.

Human raters score the first 10 results on a scale from 0 to 4; 0 means the result is completely irrelevant to the query and 4 means the result is a perfect match. The raters are medical professionals with the training and experience to evaluate the relevance (based on physiological or pathological relationships) of the retrieved documents to the original search queries.
In our experience, it takes one rater roughly one week to label a case and requires about one hour per week for maintenance because both search engine and content always changes. We estimate that one human rating costs us about €1, thus one complete case costs around €1500. Utilizing experts to create judgment lists for offline evaluation is cost-intensive.
What are large language models (LLMs)?
LLMs, like OpenAI’s GPT series, are advanced AI systems that excel at language processing and generating human-like text. These models are trained using massive amounts of data, enabling them to generate contextually relevant and coherent responses across a wide range of topics. By leveraging their vast knowledge base and powerful neural networks, LLMs have become indispensable tools in fields such as natural language processing, content generation, and translation.
However, LLMs do not maintain a knowledge base of facts. Hence, LLMs cannot reason the way a human would. After ChatGPT was released at the end of 2022, early adopters from various disciplines pushed the limits of what LLMs can do. And while it might be too early to determine their full potential, LLMs already appear to have transformational potential across a wide range of industries including health technology and medicine.
How can we use LLMs to create judgment lists?
Since LLMs don’t “understand” physiology or pathophysiology, they cannot deduce if search results are relevant for a given query.
For example, an LLM could not replicate a medical professional’s reasoning that for a user that queries AMBOSS for ‘Kayser-Fleischer rings’, a copper accumulation in the descemet membrane that is a clinical feature of Hepatolenticular degeneration, the article about Wilson disease is very relevant to the search term. An LLM will answer every question asked, including, “Is an article about ‘Wilson disease’ related to the search query ‘Kayser-Fleischer rings’?” but only based on the statistical probability of words appearing in proximity to one another and not based on factual knowledge combined with deductive reasoning.
To determine the potential utility of LLMs in search evaluation, we compared the performance of an LLM to human expert raters.
Experiment
We used the OpenAI GPT API and instructed the model to rate queries and their search results with a few different system prompts (the instructions on the left-hand side of the screenshot) and provided the model with different levels of context (the user input in the middle). To understand errors, we looked at the model’s rationale, which is provided on request and compared performance of the same prompt with GPT-3.5 and GPT-4.
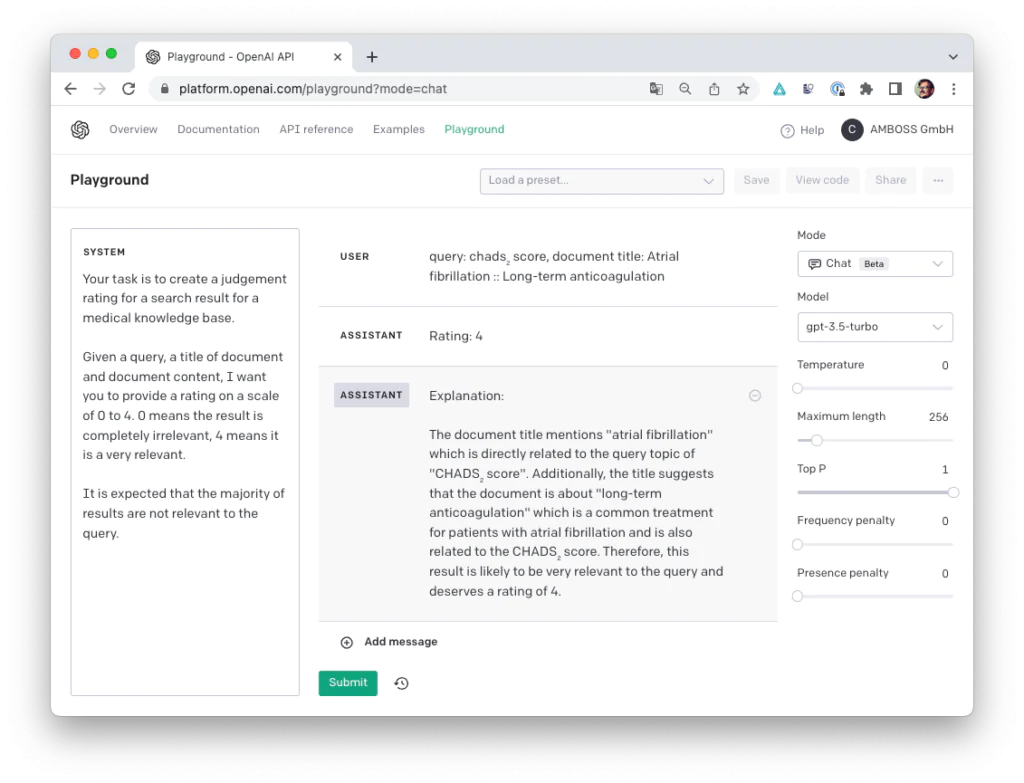
We then used the program to provide judgments for all 1500 queries, document titles, and document content tuples for a complete case that had already been rated by a human and compared the predicted labels from GPT to the ratings provided by our human experts. To assess accuracy, we looked at mean absolute error and Cohen’s kappa coefficient for inter-annotator agreement between human raters and GPT and inspected confusion matrices.
Prompt engineering
To iteratively improve the prompts for GPT, we manually inspected the results and made general improvements. Interestingly, adding details to the query yielded similar improvements to using a more sophisticated model. Although this isn’t surprising, as we’ve found that better data often outperforms more complex models when using other machine learning applications.
After the first run, we noticed that for GPT, a query from the field of medicine and a medical article are already related. Of course, since all of our data is in the medical domain, this doesn’t hold true. So we added the sentence, “It is expected that the majority of results are not relevant to the query” to inform the model about the expected class imbalance.
The prompt was further improved by evaluating the types of errors made by the GPT model (Error Analysis). After looking at the queries that were incorrectly labeled by the model, we found that many errors were related to the use of medical abbreviations. Therefore, we added the sentence, “Some of the queries will be lowercase medical abbreviations that should be interpreted” to the GPT prompt.
Results
We used mean absolute error to determine the accuracy of GPT’s labeling capabilities. We also calculated Cohen’s kappa coefficient to assess the degree of agreement between GPT and our human raters.
Initial performance was mediocre. After informing the model about the expected class imbalance, performance improved by 23%. We achieved an additional 26% improvement by changing the model to GPT-4 with the same prompt. Adding the task to interpret medical abbreviations resulted in a 4% improvement against the tuned GPT-4 prompt.
| Model name | Mean absolute error | Cohens kappa coefficient κ | Cost |
| Vanilla Query GPT-3.5 | 1.765498652 | 0.0766 | $1.50 |
| Tuned Query GPT-3.5 | 1.353658537 | 0.1048 | $1.60 |
| Tuned Query GPT-4 | 0.9919137466 | 0.1713 | $16 |
| Tuned Query GPT-4 with abbreviations | 0.9513513514 | 0.195 | $16 |
The mean absolute error of the best experiment was < 1 (0.95). So on average, the predicted rating was less than 1 class off. Cohen’s kappa coefficient was κ=0.195, which can be interpreted as “slight agreement” between the human raters and GPT (Viera AJ, Garrett JM. Understanding interobserver agreement: the kappa statistic. Fam Med, 2005;37:360–363).
The confusion matrix (a tabular view of the prediction outcomes of a classifier for a test set) indicates that removing precision classes and adopting a binary classification (0,1: irrelevant vs. relevant) will further boost performance.
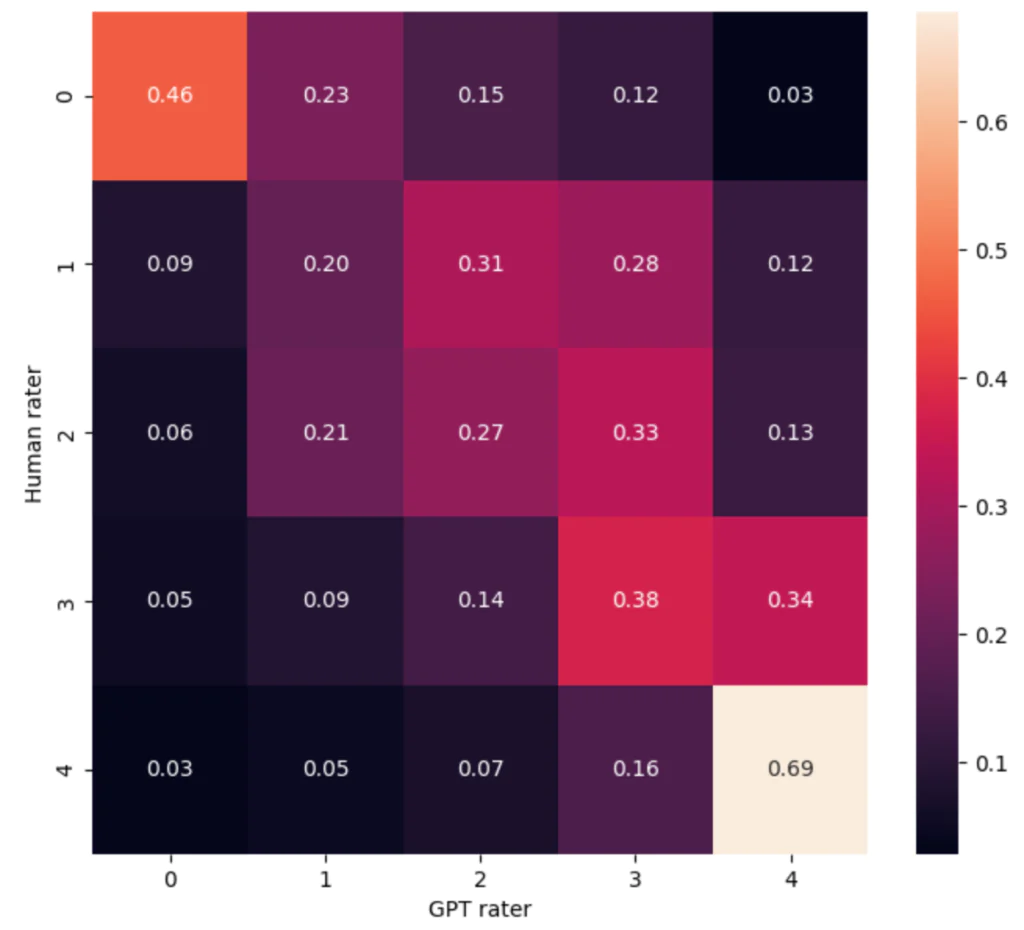
Limitations
For cost and efficiency reasons, we didn’t measure inter-annotator agreement. Inter-annotator agreement would involve giving the same dataset to two human raters and comparing their ratings by calculating the mean absolute error and Cohen’s kappa coefficient. Therefore, we cannot take human error (which is unlikely to be 0) into account when comparing human raters to the LLM.
LLMs and search engines share a lot of technology and ideas when it comes to natural language processing. If we operationalized this approach, we’d have to avoid using the same tools and techniques in the evaluation step and the engine we want to build to avoid an unfair comparison. For example, if we use an LLM in the query understanding step of our search pipeline and use the same LLM to evaluate results, we would be prone to generating biases. The role of gold standard data is to have an unbiased, perfect dataset to compare results against, and, therefore, the utility of an evaluation step that doesn’t guarantee unbiased results during search engine development is unclear.
The results should not be interpreted as benchmarking the medical reasoning capabilities of LLMs because the dataset we are working with is very specialised. Conclusions about the general applicability of LLMs to the medical domain should not be drawn.
Next steps
- Measure inter-annotator agreement between human raters and obtain a realistic κ for human raters.
- Further improve the prompt (e.g., by adding examples) to increase accuracy.
- Batch all results for a query together to improve cost and potentially improve accuracy.
- Use the GPT-3.5 fine tuning API to reduce cost, improve latency, and increase accuracy.
- Include more context, such as a repository of all available AMBOSS articles, with the labeling task.
- Simplify the rating scale to only two classes (relevant , irrelevant) to improve accuracy.
Conclusion
We were surprised by the quality of the ratings even after a very short experimentation and tuning phase. Even though LLMs don’t have any understanding of the human body or its pathologies, the model successfully estimates the medical relevance of documents to queries better than chance.
Even after the first few potential accuracy improvements, the results are already usable: There is slight agreement between human raters and GPT. Big accuracy improvements were achieved by configuring the model, but also through prompt engineering, which underlines the importance of this emerging discipline.
Human ratings cost ~ €1, and we get GPT-4 ratings for $0.1 and GPT-3.5 ratings for $0.01. As GPT-3.5 is two orders of magnitude cheaper than human raters, it would allow us to create 100–1000 times the number of labels for the same investment. The labels can also be created quickly using massive parallelism, without any onboarding time or significant work delay (minutes rather than weeks).
If the accuracy of the LLM-based labeling can be increased further, the availability of very cheap ratings with sufficient accuracy could greatly improve the evaluation quality and accuracy of our search engine.
Related reading
Turnbull D, Berryman J, Relevant Search, Chapter 10.7 describes the methodology for the offline evaluation of Search engine relevance.
Intuition for Cohen’s kappa coefficient is in Viera AJ, Garrett JM. Understanding interobserver agreement: the kappa statistic. Fam Med, 2005;37:360–363
Authors
Valentin v. Seggern and Daniele Volpi from AMBOSS wrote this article. Please get in touch, if you are curious about LLM evaluation, have access to LLMs especially tailored to the medical domain or have a large dataset of human labeled gold standard data that you want to use to evaluate LLMs in niche domains.
