Overcoming data silos
Building cross-functional alignment in a hyper growth company

Everyone talks about data and how important it is to increasing business growth these days. For me, data has always been one of the most important factors in my personal and professional life. What I believe is not being spoken about enough though, is that there’s a price for getting the most out of your company’s data.
As organizations grow, data silos can emerge. When different teams within a company begin collecting and curating data on their own, overlaps with other teams can materialize. At this stage, teams aren’t sharing and communicating, hence the appearance of data issues.
This arises because as business leaders, we crave more insights and prefer looking at data on visualized graphs or dashboards. But behind the glamor of powerful analytical insights is a hidden backlog of tedious data acquisition, preparation, storing, cleansing, sharing, archiving, deleting and usage.
We need to continuously improve on this data while maintaining it.
Imagine the following situation:
Team B starts collecting and curating data for metric X, that has been defined internally in team B.
Team A has already had data collection and curation in place for some time to calculate their metrics. They have one metric, also called metric X, which is defined and used only by team A.
Both team A and team B prepare monthly/quarterly reports for the C-level without knowing that they’re both using metric X, and that it has two definitions. Because metric X is defined and calculated differently in teams A and B, it’s normal that the reports of these two teams don’t reflect the same insights.
This leads to confusion among the report receivers, who are usually decision makers. They then ask: which report is the reliable one?
Teams A and B start improving on these reports from within their silos, without really collaborating to address the root cause of the problem — the definition of metric X.
If metric X isn’t defined and agreed upon across all of the departments, it won’t bring value to the company. The data team wouldn’t be able to ensure a data quality approved report.
I believe that continuous improvement is not always the best solution. It won’t dissolve data silos and doesn’t solve the root cause of many problems data teams face.
Sometimes the best thing to do is start over with something new.
I love this quote from Oren Harari which I believe explains this very clearly:
“The electric light bulb did not come from the continuous improvement of candles.”
You can’t improve on a baseline of candles hoping that you’ll eventually create a lightbulb. With data infrastructure, ensuring that your baseline is ready for continuous improvement, and understanding when continuous improvement won’t get you where you need to go, is crucial.
If you don’t have a proper baseline or infrastructure in place, no matter how many improvements happen within your data silos, you’ll never get to a single source of truth for decision making.
Additionally, building data democratization within a company is only possible if you know your data well. You can only know your data if you treat it as real asset, have a single source of truth for your core concepts, enterprise-wide definitions, and proper data infrastructure in place to access data.
Once you have these prerequisites, you can build a self-service solution for data consumers within the company.
After reading this article I hope that you, as a data advocate and enthusiast, will better appreciate data quality and why it’s important to break down data silos in the early stages of a company’s growth. I also hope you’ll take away some ideas of how to do so, and share your own experiences.
“If you don’t have a proper baseline or infrastructure, no matter how many improvements happen within your data silos, you’ll never get to a single source of truth for decision making.”
Data Silos Appear When Data is Abandoned
Based on my decade experience in the data field, data silos are generated whenever data is abandoned and not taken as a real asset.
What do I mean by abandoned?
Data acts as a bridge between business functions, technology and product. When it’s left under the supervision of either business or technology and product, the bridge is broken, data is abandoned, and data silos occur.
If data is led by tech and product, business growth and continuity will suffer. If it’s led by business, it won’t benefit from the fast pace of technological modernization, and may lead to a huge tech debt one day. Both mentioned approaches are common, and the lack of attention paid to data during both the early and growth stages is unfortunately a global norm.
This lack of a proper strategy for data acquisition, collection, and curation leads to low data quality and frustration within many departments in the company. Different teams may have trouble finding the data they need, which can negatively impact their work and decision making.
99% of the time this problem is addressed by a short-term vision and quick fix — let’s hire a data analyst for our team/department.
This short-term solution does temporarily solve that individual team’s problem, and word of the short-term successful experience travels to other teams in the company. This is one common way data silos are created.
There can also be other root causes of the overarching data silo problem, such as:
- A lack of considering data as a real asset with proper data life cycle management (DLC), data ownership, and data governance. This threatens the business continuity from different aspects such as; dissatisfaction of customers due to wrong or low quality reports, undetected fraud or data breaches, increasing complexity and risk management, poor decision making, and regulatory management.
- The existence and dependencies of various programs/software applications on different fast growing teams (or disparate systems). This will cause the company to suffer from increased tech debt, complexity in its infrastructure, and the inability to make any amendments or improvements over time.
Regardless of the root cause, data silos lead to poor data quality due to fragmented data ownership. This is normally driven by multiple stakeholders from different departments who have different definitions for similar terms/KPIs/metrics. Data quality cannot be measured across the whole company, but is rather measured at the team level because of a lack of enterprise-wide definitions.
Hiring data analysts for different teams, who have different expectations and skill sets but the same title, can also negatively impact both the business and its employees.
- For companies, an increase in costs and decrease in quality and efficiency of the workforce could happen. You might not need eight analysts, one on each team for example, you might only need three analysts total in a cross-functional setup.
- There might also be an increase in data discrepancy. Each analyst prepares a report based on their team’s knowledge rather than from a company-wide perspective.
- Analysts may have different skills and aren’t following a clear, unified job description. Because they have the same title, they could also start comparing themselves to each other, leading to employee dissatisfaction. Being on separate teams, they’ll also miss opportunities to learn from each other.
Eliminating Data Silos
Eliminating data silos can happen in different ways — defining a proper data strategy and promoting a data culture, centralizing all data integrations, or setting clear expectations. Introducing a more defensive strategy (i.e. defining and enforcing standards), and transparently sharing what we’re doing and why we’re doing it, has helped me kickstart projects in the past.
Following this approach, I’ve focused on two parallel projects:
- Training and coaching the team of data engineers, analysts and scientists on applying data and business standards to their work, such as CRISP-DM, requirement engineering, dependency check lists, data discovery sessions and documentation, DV modeling, BEAM, and BPMN. This has helped the team not only develop their knowledge on the data field but also get closer to the business, understanding the impact of their work on business continuity more clearly.
- Improving data literacy among key stakeholders outside the data team by presenting the results of the above strategy.
The challenge in this approach is scaling up successful minimum viable products (MVPs) and proof of concepts (POCs).
To address these, I use short and long-term goals in my data roadmap which need strong support from key stakeholders and decision makers:
- Short-term — this involves organizational changes, such as putting all data-related positions under one umbrella team. The goal here is to unify all domain knowledge into one knowledge-pool to better support data consumers within the entire company. You’ll need an agreement from all major stakeholders on top priorities for a time frame of 4–9 months to build the foundational elements of your data architecture, assuming you already have a strong team of at least 5 senior data engineers (the number of data engineers needed is generally defined based on the maintenance needs of the existing data ecosystem, modernizing the data infrastructure including pipelines, data warehousing, reporting, and analytics, and supporting the growth of the company).
- Long-term — this is planned based on the results of the short-term goals and the lessons learned, along with main objectives to ensure business competitiveness and continuity.
The long-term goals are:
- Bringing your data culture to the next level— from reactive, to proactive, managed, and finally predictive
- Advanced analytics for anomaly detections, forecasting and prediction perspectives
- Ensuring compliance with regulations (e.g. GDPR and privacy, financial IFRS, etc.), and
- Maximizing data quality and availability to ensure business continuity
In order to get rid of data silos, people’s data habits (how they work with data on a daily basis) need to shift.
Changing Habits Associated with Data Silos Requires Alignment and Trust
Alignment is the most challenging part of overcoming the effects of data silos — separated and isolated teams with specific domain knowledge usually have ways of working that aren’t aligned with other teams.
Introducing processes that focus on wider communication, transparency, and documentation of requirements with stakeholders can facilitate alignment across teams/domains.
However, for this way of working to bear fruit, you need to build an environment based on trust and where knowledge-sharing is encouraged— which takes time. Any habit change needs time and discipline to be successful.
Each silo has its own domain knowledge, that to a large extent is hidden from the other silos. People might generally know which team works on which domain, but they’re not deeply involved and miss vital context. For instance, KPI X can exist in Team A and Team B, but with 2 different definitions and calculations (most often for good reasons within the team’s domains).
Often, both teams are not aware of the impact of those differences and the confusion they create for people outside of those teams. This happens when, for example, decision makers (C-level) want to use those KPIs to make strategic decisions.
This type of issue can be widespread, and might need the new unified data team to step back and gain understanding on how the business operates, and on the entire lifecycle of the data that is collected and used.
Standards and Methods
CRISP-DM and BPMN
I’ve used Cross-Industry Standard Process for Data Mining (CRISP-DM) for more than a decade and observed its benefits. You’ll find all six phases of this process in the diagram below. I find its first and second phases (Business Understanding and Data Understanding) are vital to the success of any data project.
For documenting the business processes and their relationships with the generated data, the Business Process Model and Notation (BPMN) method is very helpful. This is used to model the detailed sequence of steps of business processes from end-to-end in a visual manner. It also enables linking each step of a business process to the related data tables, data events, etc.
These standards are important because they ensure a unified understanding of both the business and data. In order to make sure that phase two, Data Understanding, is correct and complete, it’s necessary to gather analysts from different domains. This guarantees you know the full story of your data (from the moment it’s born and collected to the moment it’s retired or deleted) well enough to transform it into the fuel for your company’s continuity and reliable decision making.
Below is a framework that I’ve developed based on CRISP-DM. It outlines how data teams work together, what each role is responsible for, and how their work affects the rest of the team.
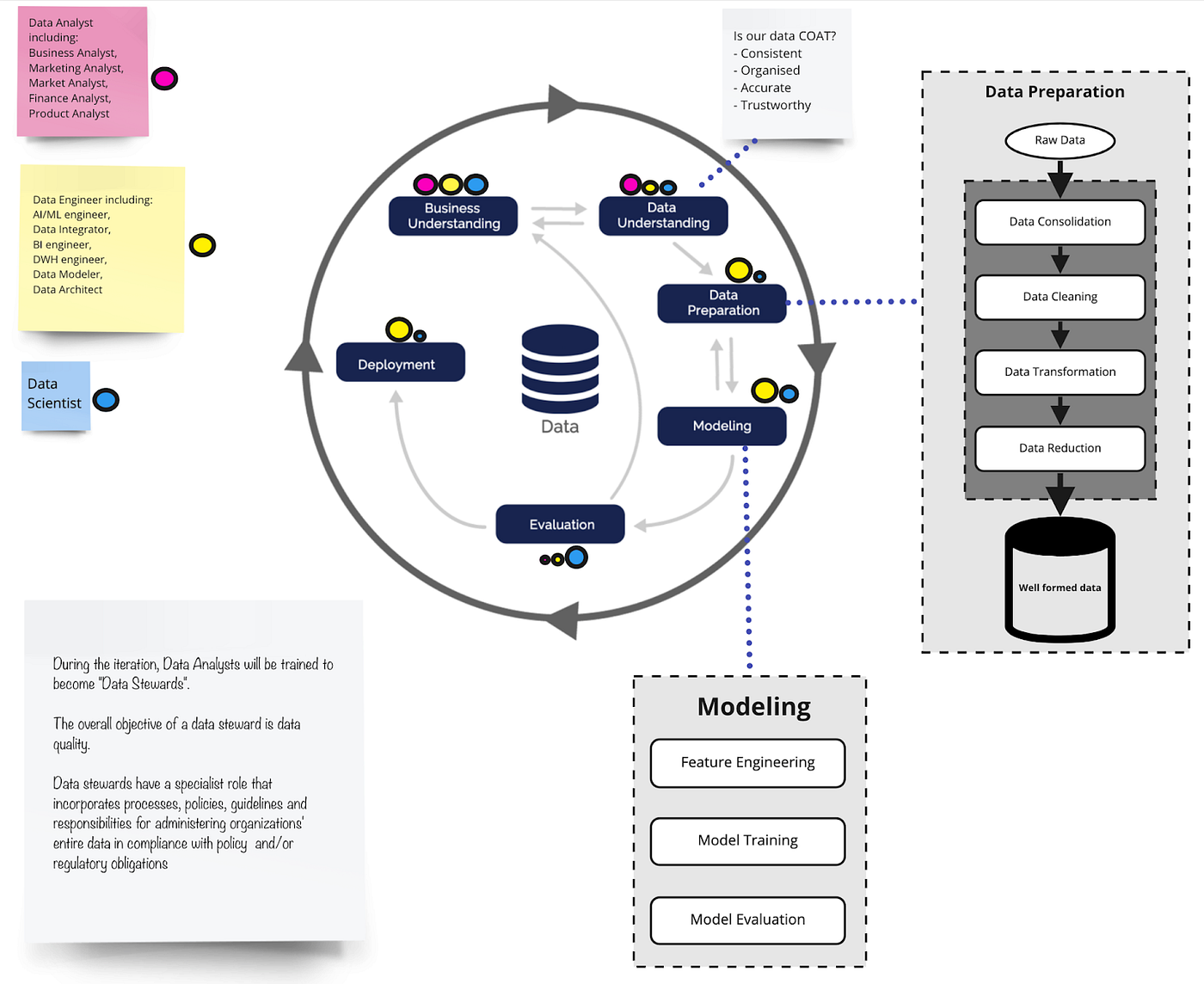
While doing this, I’ve learned to appreciate the mix of visions each member of the unified data team brings.
BEAM and Data Vault Modeling
We’ve been using the following techniques to design a robust data warehouse:
BEAM (Business Event Analysis and Modeling) is a set of collaborative techniques for “modelstorming” BI data requirements and creating inclusive, understandable models that fully engage BI stakeholders. (ref. Agile Data Warehouse Design, by Lawrence Corr)
Data Vault can be used to model the Enterprise Data Warehouse which is optimized for integration, historization and agility requirements. (ref. Modeling the Agile Data Warehouse with Data Vault, by Hans Hultgren)
Leading the Team Through Change
The thing that has stuck with me after ten years of building data teams is that an open mindset and proper attitude within the team is the key success factor to removing data silos — not skills.
Skills can be learned. With active mentoring, coaching, and the right attitude, you would be surprised at how fast a data team can become productive.
Here are some lessons I’ve learned along the way
- Those who weren’t technically skilled but were collaborative and open to change pushed further than I expected
- Those who were capable but were in their comfort zone and not ready for change had trouble adapting
- You need to define team principles and put some rules in place
Unifying data silos has a huge impact on the team’s work. But encouraging team members to come out of their comfort zones also has a price — you might lose the ones who aren’t eager to adapt to change.
Those who stay will go through the ups and downs together with you. If you have an infrastructure that’s tightly integrated into your product or service, you should be careful not to lose your most knowledgeable team members— especially if they’re resistant to change.
Sometimes you can combine your personal interests with those of your team.
I love books, so I created a book club to build alignment across my team. We would all read one book on a relevant data topic together. This was broken down into sections of around 100 pages each, and followed up with exercises they would need to complete that week. Each person would dedicate 5–10% of their working week to this.
There are various ways to keep a team motivated, make it embrace change, go through the difficult moments, and celebrate. It’s important to remember that a skilled, aligned, and motivated team is absolutely necessary to achieve this transformation.
The Importance of Transparent Communication
Building cross-functional alignment while removing data silos requires transparent communication. This isn’t just talking— it’s also setting priorities and expectations within the newly established data team and among stakeholders.
This, combined with respect, allowing team members to participate in projects that energize them, and coaching and up-skilling the team, builds the trust a project like this needs to succeed.
To help those on my team who like a big picture overview of a project, such as removing data silos, but need individual steps, I’ve used the Salami Technique.
This involves creating step-by-step guidelines, or slices of the project, while providing an overview of the end result. It makes the project seem less risky and overwhelming. Plus, it’s easy to see the value of each task with clear step-by-step planning.
Conclusion
I believe that businesses will become even more reliant on data in the following years. That means it’ll become even more important to get rid of existing data silos, or abandoned data, as soon as possible. Sometimes that might mean iterating on a baseline, other times it might mean starting over with something new.
Most importantly, it means creating a team culture that’s based on communication and trust, on top of technical skills.
Building trust comes in many shapes and forms, and everyone has their own ways of approaching it. I suggest drawing upon your passions and the things you enjoy doing — others will follow your enthusiasm!
Understanding and communicating the complexities and interdependencies of your projects, especially ones that involve people from different teams, are crucial to their success. You should also be able to address the concerns that come along with this.
And with trust, you’ll see that your team will start working together.
Are you part of a data team that’s working on overcoming data silos? Leave a comment below explaining what’s worked well for you!